
Transformer
Published:
In this blog, I will introduce the transformer architecture, which is the foundation of modern large language models. For better illustration, I will take translation task as an example.
Encoder-Decoder Transformer
This is the original transformer architecture proposed in the paper “Attention Is All You Need”.
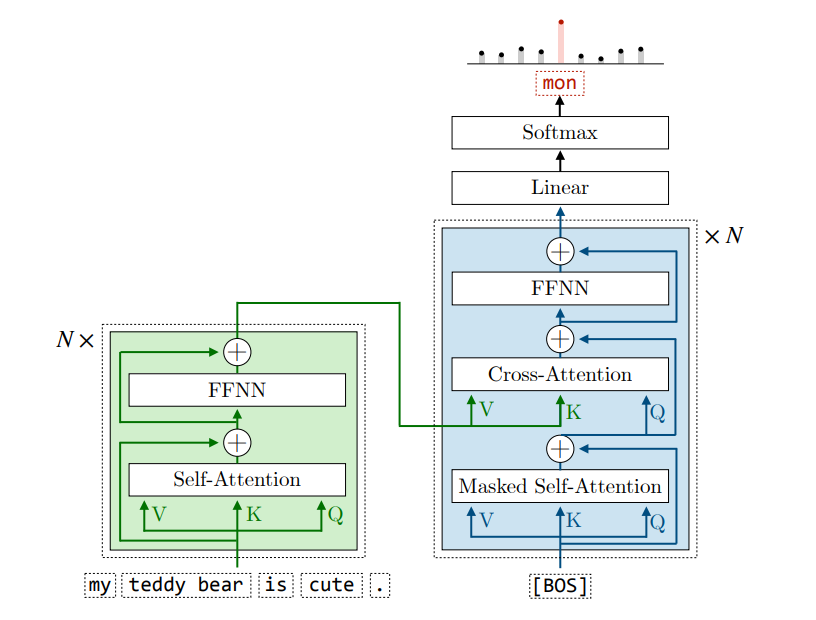
Encoder
The encoder in the Transformer architecture is designed to learn rich, contextualized representations of the input token embeddings. Instead of processing tokens in isolation, it aggregates global context, allowing each token’s representation to reflect its semantic relationship with the entire input sequence.
An encoder is composed of a stack of \(N\) identical encoder layers. Each layer consists of two primary sub-layers, accompanied by residual connections and layer normalization:
- Multi-head Self-Attention (MHA): The input embeddings are token emebddings added with positional encodings.
- Feed-forward Network (FFN): The output of the MHA layer is then passed through a feed-forward network, which consists of two linear transformations with a non-linear activation function (typically ReLU or GELU) in between.
Decoder
The decoder in Transformer use the encoded token embeddings from the source sentence to generate the translation token by token.
An decoder layer consists of three parts:
- Masked Multi-head Self-Attention (MHA): The input is the embeddings of the decoded tokens (If none has been decoded, it will be the embedding of [BOS], standing for begin of sentence) added with positional encodings. The output can be seen as the contextualized embeddings of the decoded tokens.
- Multi-head Cross-Attention (MHA): Notice that in the decoder, the MHA is thr cross-attention, meaning that the attention operates on: Q from the previous MHA layer, K and V from the encoder. \(QK^T\) is the similarity between the decoded tokens and the source tokens.
- Feed-forward Network (FFN)
- Residual Connection & Layer Normalization
Let’s end this blog with a simplified implementation of the encoder-decoder Transformer and a translation task.
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
# Vocabulary Definition
SRC_VOCAB = {"<PAD>":0, "<SOS>":1, "<EOS>":2, "i":3, "love":4, "you":5}
TGT_VOCAB = {"<PAD>":0, "<SOS>":1, "<EOS>":2, "我":3, "爱":4, "你":5}
TGT_IDX2WORD = {v: k for k, v in TGT_VOCAB.items()}
src_seq = torch.tensor([[1,3,4,5,2]])
tgt_in = torch.tensor([[1,3,4,5]])
tgt_out = torch.tensor([[3,4,5,2]])
d_model = 16
def self_attention(Q, K, V, mask=None):
"""
Q,K,V: [batch_size, seq_len, d_model]
"""
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(Q.size(-1))
if mask is not None:
scores = scores.masked_fill(mask==0, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, V)
return output
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_model*4),
nn.ReLU(),
nn.Linear(d_model*4, d_model)
)
def forward(self, x):
emb = self.embedding(x)
Q = self.W_q(emb)
K = self.W_k(emb)
V = self.W_v(emb)
attn_out = self_attention(Q, K, V)
out = attn_out + emb
out = self.ffn(out) + out
return out
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.W_q_self = nn.Linear(d_model, d_model)
self.W_k_self = nn.Linear(d_model, d_model)
self.W_v_self = nn.Linear(d_model, d_model)
self.W_q_cross = nn.Linear(d_model, d_model)
self.W_k_cross = nn.Linear(d_model, d_model)
self.W_v_cross = nn.Linear(d_model, d_model)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_model*4),
nn.ReLU(),
nn.Linear(d_model*4, d_model)
)
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, x, enc_out):
seq_len = x.size(-1)
emb = self.embedding(x)
causal_mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0).to(x.device)
Q_self = self.W_q_self(emb)
K_self = self.W_k_self(emb)
V_self = self.W_v_self(emb)
self_attn_out = self_attention(Q_self, K_self, V_self, mask=causal_mask)
self_out = self_attn_out + emb
Q_cross = self.W_q_cross(self_out)
K_cross = self.W_k_cross(enc_out)
V_cross = self.W_v_cross(enc_out)
cross_attn_out = self_attention(Q_cross, K_cross, V_cross)
cross_out = cross_attn_out + self_out
ffn_out = self.ffn(cross_out) + cross_out
logits = self.fc_out(ffn_out)
return logits
encoder = Encoder(len(SRC_VOCAB), d_model)
decoder = Decoder(len(TGT_VOCAB), d_model)
optimizer = torch.optim.Adam(list(encoder.parameters()) + list(decoder.parameters()), lr=0.01)
criterion = nn.CrossEntropyLoss()
print("Start Training")
for epoch in range(100):
optimizer.zero_grad()
enc_out = encoder(src_seq)
logits = decoder(tgt_in, enc_out)
loss = criterion(logits.view(-1, len(TGT_VOCAB)), tgt_out.view(-1))
loss.backward()
optimizer.step()
if (epoch + 1) % 5 == 0:
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
enc_out = encoder(src_seq)
curr_tgt = torch.tensor([[TGT_VOCAB["<SOS>"]]])
MAX_LEN = 5
print(f"Initial State: {[TGT_IDX2WORD[idx.item()] for idx in curr_tgt[0]]}")
for step in range(MAX_LEN):
logits = decoder(curr_tgt, enc_out)
next_word_logits = logits[0, -1, :]
next_word_idx = torch.argmax(next_word_logits).item()
next_word = TGT_IDX2WORD[next_word_idx]
print(f"Step {step+1} predicts: {next_word}")
if next_word == "<EOS>":
break
next_word_tensor = torch.tensor([[next_word_idx]])
curr_tgt = torch.cat([curr_tgt, next_word_tensor], dim=1)
print(f"Current State: {[TGT_IDX2WORD[idx.item()] for idx in curr_tgt[0]]}")
print(f"\Result: {[TGT_IDX2WORD[idx.item()] for idx in curr_tgt[0]][1:]}")
In next blog, I will introduce the decoder-only Transformer architecture, which is widely adopted by SOTA LLMs like ChatGPT. I will also introduce some advanced features such as the positional encoding and KV cache.