
Embedding
Published:
In the world of machine learning, we use embeddings(mathematically speaking, vectors) to represent everything. In this post, I will introduce how to encode nature languages into embeddings.
The embedding process consists mainly two steps:
- tokenization
- embedding
Tokenization
Tokenization is the process of breaking down a text into tokens. So a token is an unit of text. Considering different granularity, a token can be a word, a subword, a character, or even a byte.
There are also some special tokens, such as [PAD], standing for padding, [UNK], standing for unknown, [CLS], standing for classification, [SEP], standing for separator.
A vocabulary is a fixed set of predefined tokens, which is used to convert the input text into tokens.
Tokenizer
A tokenizer \(T\) is a function that maps a text \(x\) into a sequence of tokens \(T(x) = [t_1, t_2, \cdots, t_n] \in \mathbb{R}^n\).
Encoding is the process of mapping a token into a vector. \(T: x \mapsto \mathbb{R}^n.\)
Decoding is the reverse process of encoding. \(T^{-1}: \mathbb{R}^n \mapsto x.\)
BPE
Now we introduce the Byte-pair Encoding (BPE) tokenizer. BPE is a tokenization method that constructs the vocabulary by learning from the most common pairs of entities that are present in the training texts.
Training steps:
- Divide the text into characters and add all of thenm into vocabulary.
- Pairing each characters with their previous and next character (for the first and last character, pairing them with next and previous one). Select the pair that occurred the most often and add it into the vocabulary.
- The selected pair will be treated as one character and repeat the pairing step, until the vocabulary has reached the desired size.
Token embeddings
Now we introduce how to embed tokens in the vocabulary into embeddings.
One-hot encodings
Given vocabulary \(V\), token i is encoded into a vector \(x_{OHE}\) with \(i\)-th element equals to 1 and other elements 0.
Noticing that embeddings are all athogonal to one another, which indicates the limiation that we cannot compute the similarity between two tokens.
Continuous encodings
Word2vec
It is based on a shallow neural network \(f\) with one hidden layer. It projects one-hot embeddings \(X_{OHE}\) into a continuous space \(X_{cont}\). The network is then optimized by minimizing the difference between \(f(X_{OHE})\) and \(X_{cont}\). Comparing to one-hot encoding, this countinuous method can capture the semantic relationship between tokens.
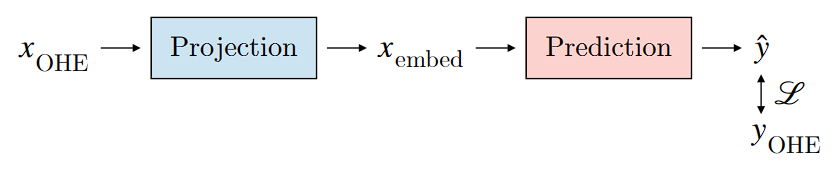
CBOW
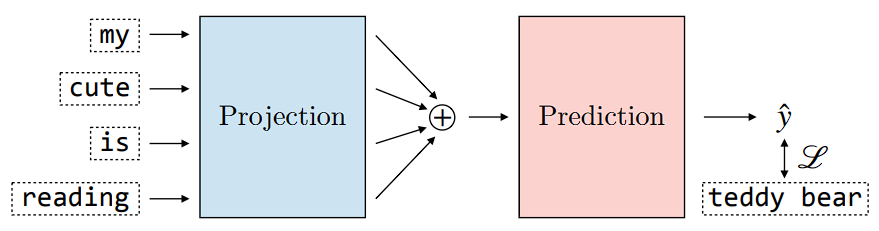
Continuous Bag-of-Words (CBOW) is a word2vec model that predicts a target token based on the average of its context token embeddings \(X_{avg}=\frac{1}{2*C+1}\sum_{i=-C}^{C}x_{i}\), where \(C\) is the context size.

It is a shallow neural network with one hidden layer. The network is then optimized by minimizing the difference between \(f(X_{avg})\) and \(X_{cont}\).
Negative Sampling
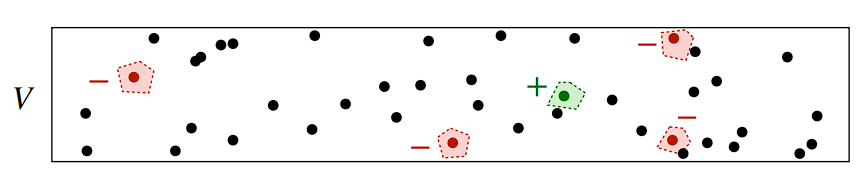
In natural language, if we have one target token embedding \(w_p\), we can randomly sample a token in its neighborhood to be the positive sample \(w_{pos}\), and \(N\) tokens out of its neighborhood to be the negative samples \(w_{neg}\), then we maximize the differences between the positive sample and the negative samples.
\[\mathcal{L}=-\log\sigma(w_p^Tw_{pos})-\sum_{i=1}^{N}\log(\sigma(-w_p^Tw_{neg_i}))\]This method is similar to the BPR-loss widely adopted in recommender systems.